
认识 Qwen3-VL —— 迄今为止 Qwen 系列中最强大的视觉-语言模型。
这一代模型实现了全方位升级:在文本理解与生成能力上更为出色,具备更深层次的视觉感知与推理能力,支持更长的上下文长度,并在空间理解、视频动态感知以及智能体交互能力方面显著增强。
模型提供 Dense 和 MoE 两种架构形态,可从端侧扩展到云端,同时支持 Instruct 版本和增强推理能力的 Thinking 版本,满足灵活、按需的部署需求。
Model Farm 提供预编译好的模型资源以及推理代码,支持以下两种方式获取:
通过 Model Farm 页面获取:在右侧性能参考板块中点击模型 & 代码获取模型资源及代码包。
通过命令获取(推荐):持有阿加犀开发板的用户,可以通过开发板内置的 MMS 工具获取模型资源及代码包。
# 模型查询
mms list [model name]
# 模型资源获取
mms get -m [model name] -p [precision] -c [soc] -b [backend] -d [file path]
MMS 具体使用请参考:MMS 使用 & 提前获取预览版块模型
主要增强特性:
视觉智能体(Visual Agent):可操作 PC / 移动端 GUI,能够识别界面元素、理解功能、调用工具并完成任务。
视觉编程能力提升(Visual Coding Boost):可根据图像或视频生成 Draw.io / HTML / CSS / JavaScript 代码。
先进的空间感知能力(Advanced Spatial Perception):能够判断物体位置、视角和遮挡关系,提供更强的 2D 定位能力,并支持用于空间推理和具身智能的 3D 定位。
长上下文与视频理解(Long Context & Video Understanding):原生支持 256K 上下文,可扩展至 1M;能够完整理解书籍级文本和数小时级视频内容,并支持秒级索引与精准回溯。
增强的多模态推理能力(Enhanced Multimodal Reasoning):在 STEM / 数学领域表现突出,具备更强的因果分析能力,能够给出逻辑严谨、基于证据的回答。
升级的视觉识别能力(Upgraded Visual Recognition):通过更大规模、更高质量的预训练,实现“万物识别”,涵盖名人、动漫角色、商品、地标、动植物等。
OCR 能力扩展(Expanded OCR):支持 32 种语言(由原来的 19 种提升);在低光照、模糊、倾斜等复杂场景下更加稳健,对生僻字、古文字和专业术语识别更友好,并显著提升了长文档结构解析能力。
文本理解能力媲美纯 LLM(Text Understanding on par with pure LLMs):实现文本与视觉的无缝融合,带来无损、统一的理解体验。
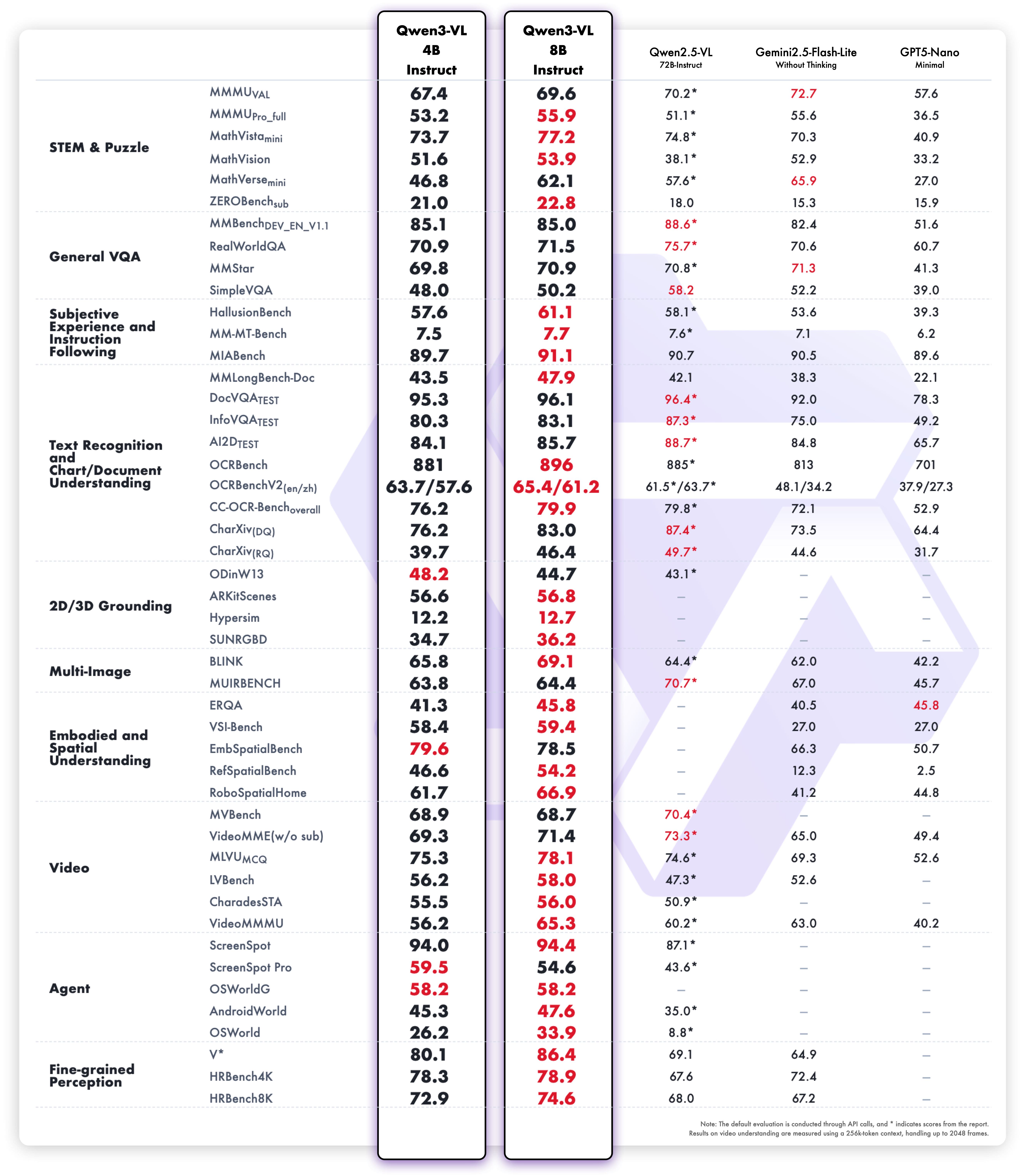
多模态性能
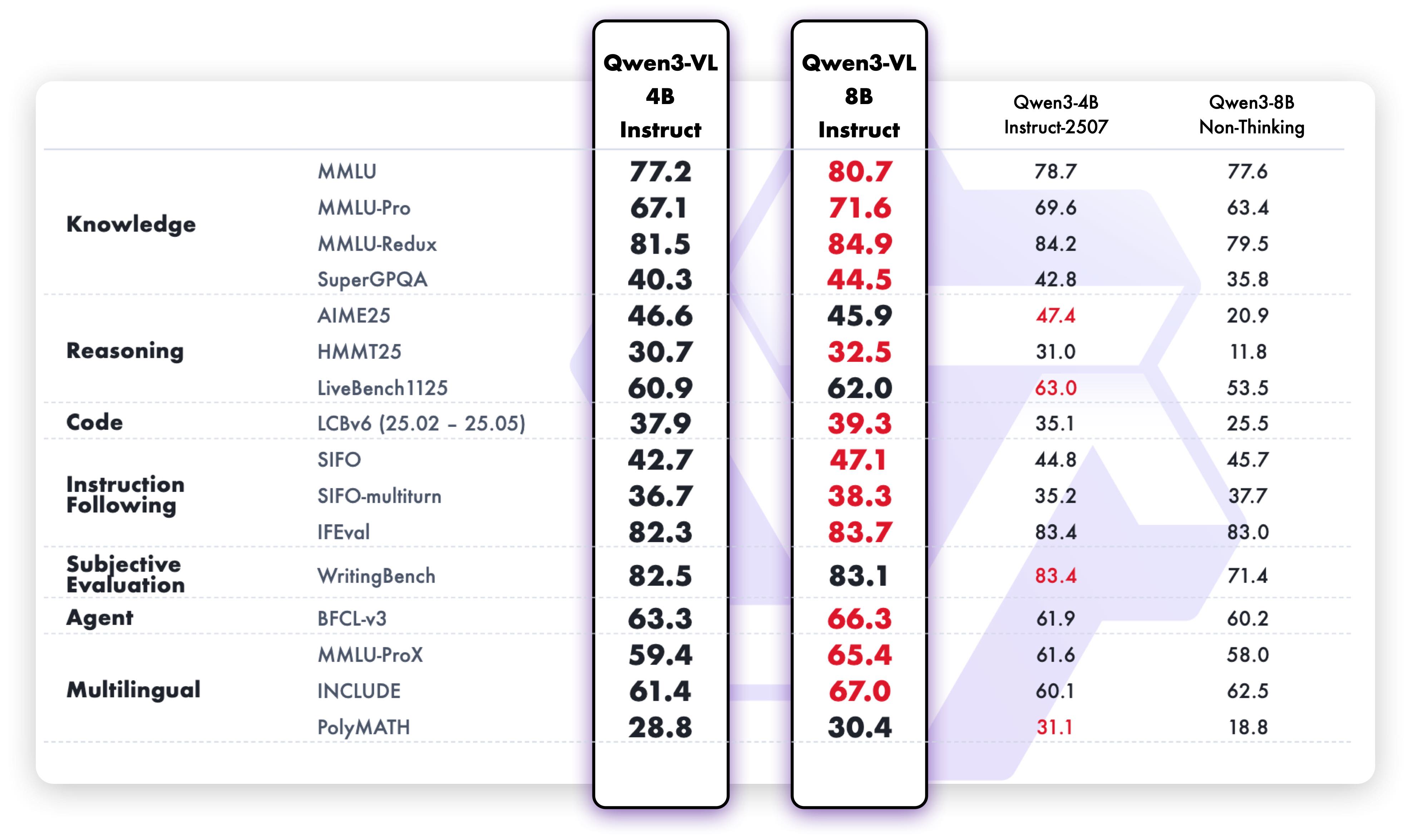
纯文本性能
待发布